検索・分析エンジンElasticsearchは、ダウンロードすればすぐに利用を開始できるOSSのツールです。高性能な機能を無料でいつでも気軽に試すことができ、シェアを伸ばし続けています。
本コラムでは、Elasticsearchに興味を持たれている方や、まずはElasticsearchを使ってみたいというユーザのために、押さえておきたい基礎知識となるデータ投入の手順を解説します。
Elasticsearchにおけるデータ投入ツールの選び方
Elasticsearchにデータを投入する際、ツールを使うことが一般的です。Elasticsearchには、公式、サードパーティを含めて様々なツールが用意されており、要件に応じて使い分けるのが一般的です。そこで、自分のやりたいことにツールが合っているかどうか、整理してみましょう。
BeatsとLogstashは、Elastic社の提供する公式ツールです。「とりあえず使ってみたい」という“お試し”のニーズならば、より軽量で手軽なBeatsから入るのがおすすめです。
Beatsは、データ収集・転送に特化したプラットフォームで、サーバやコンテナに展開するだけでデータを集約できる簡便さが特長です。特に、以下のようなデータの扱いに適しています。
▼Beats対応データの例
ログファイル、メトリック、ネットワークパケット、Windowsイベントログ、監査データ、稼働状況の監視
Logstashはサーバ向けデータパイプラインとして、ログやメトリック、Webアプリケーション、データストア、さらには様々なクラウドサービスからのデータを収集し、Elasticsearchへ継続的に投入します。Beatsが収集・転送したデータを受け取り、さらに高度な処理を行うといった使い方も一般的です。
Elasticsearchと各ツールの関係
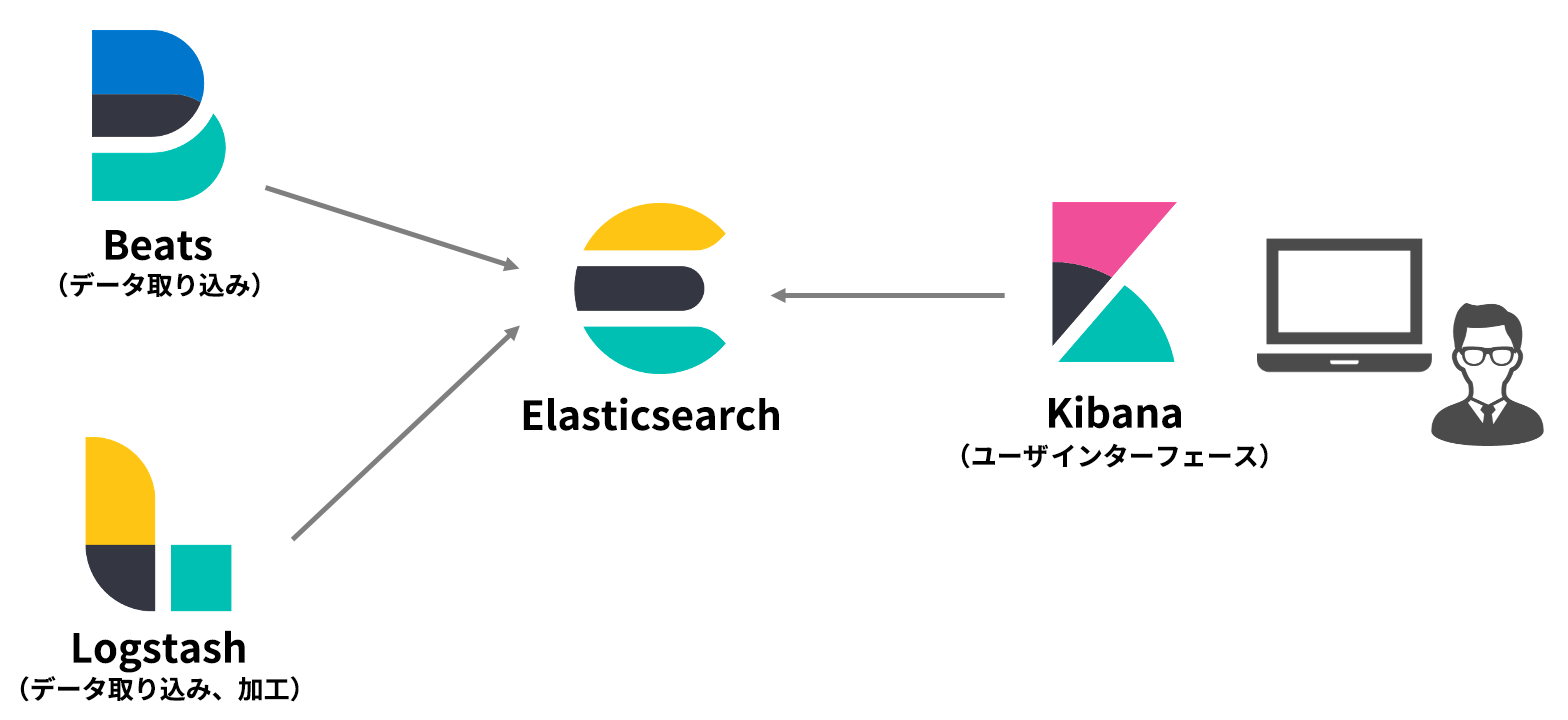
ツール選定で重要なのは、対応データ形式です。多くのデータ形式に対応し、使い勝手の面でも定評ある公式ツールですが、ファイルサーバやExcelといったバイナリドキュメントには対応していません。こうしたデータの検索・分析ニーズがある方は、サードパーティ・ツールを使って補完していくことが必要になります。例えば、ファイルサーバやWebの検索・分析を得意とする全文検索の「Fess」、PDF、MS Officeなどのバイナリドキュメントのインデックス作成に適した「FSCrawler」などが有名です。
ツール別データ投入の方法
それでは、実際にデータをElasticsearchに投入してみましょう。ここではBeatsとLogstashの手順を紹介します。
【1】Elasticsearchへのデータ投入:Beats編
Beats には、検索・分析するデータの形式に応じた様々な公式のシッパーが用意されています。ログファイルに特化したFilebeat、システム統計情報を収集するMetricbeatをはじめ、Packetbeat(ネットワークパケット)、Winlogbeat(Windowsイベントログ)、Auditbeat(Linuxの監査フレームワークデータ)、Heartbeat(プロービングによるサービスの稼働監視)など、ラインアップは多様です。
ここでは、Filebeatを例に説明しましょう。Filebeatはサービスやアプリ、ホスト、データセンターなど、様々な場所に存在するログやファイルを収集します。
Elastic社の公式サイトからFilebeatをダウンロードし、インストールを終えたら、ログの参照先や出力先のファイル設定を行いましょう。まずは「filebeat.yml」を作成し、Filebeatディレクトリのトップに保存します。
また、今回の動作確認では以下のようなサンプルログデータを使用します。
●サンプルログデータ: 202106_log.csv
Date,ID,contents 2021-06-01 09:00:00,1,Success. 2021-06-02 10:00:00,2,Success. 2021-06-03 11:00:00,3,Success. 2021-06-04 12:00:00,4,Error. 2021-06-05 13:00:00,5,Success. 2021-06-06 14:00:00,6,Error. ●設定ファイル: /usr/share/filebeat/filebeat.yml
その後、次の手順で進めてください。
filebeat.inputs: -type: log paths: - /usr/share/filebeat/log/*.log output.file: path: "/usr/share/filebeat/output" filename: filebeat 【2】Elasticsearchへのデータ投入:Logstash編
まずは公式サイトからホスト環境に合った Logstash installation fileをダウンロードし、サポートされるLinuxオペレーティングシステムで、パッケージマネージャを使用してください。その後、設定ファイルを作成します。ここではCSVファイルの取り込み方を説明します。
●設定ファイル: config/logstash.conf
input { file { mode => "tail" path => ["/log/*_log.csv"] sincedb_path => "/sincedb/*_log.csv" start_position => "beginning" codec => plain { charset => "UTF-8" } } } filter { csv { columns => ["Date", "ID", "contents"] convert => { "ID" => "integer" } skip_header => true } date { match => ["Date", "yyyy-MM-dd HH:mm:ss"] } } output { elasticsearch { hosts => "localhost:9200" index => "log" } stdout { codec => rubydebug } } このconfファイルの各設定の意味は次のとおりです。
▼input設定
mode => "tail" ファイルの取り込みモードを指定します。
Tail:ファイルの変更を検知し、追加分のデータを新たに取り込みます。
Read:ファイルは更新されないものとして扱われます。
path => ["/log/*_log.csv"] 取り込んだファイルのパス(ここでは_log.csv)を指定します。
sincedb_path => "/sincedb/*_log.csv" sincedbファイルのパスを指定します。sincedbファイルはデータをどこまで取り込んだのか追跡するためのファイルで、再起動などの際の差分の見逃しを防ぎます。
start_position => "beginning" ファイルの取り込み位置を指定します。
beginning:ファイルの先頭から
end:ファイルの末尾から
codec => plain { charset => "UTF-8" } ファイルの文字コード(デフォルトはUTF-8)を指定します。
▼filter設定
columns => ["Date","ID","contents"] カラム名を指定します。
convert => { "UserId" => "integer" } カラムのデータ型を指定します。
skip_header => true ヘッダー行の読み込みをスキップさせます。
date { match => ["Date", "yyyy-MM-dd HH:mm:ss"] } タイムスタンプの日時フォーマットを指定します。
▼output設定
elasticsearch { hosts => ["localhost:9200"] index => "log" } Elasticsearchの出力先URIとインデックス名を設定します。
stdout { codec => rubydebug } コマンドプロンプトへの指定します
●データの取り込み
実際にデータをコマンドプロンプトに出力します。
実行コマンド
/usr/share/logstash/bin/logstash -f /conf/logstash.conf 実行結果
{ "path" => "/log/20210603_log.csv", "@version" => "1", "ID" => 4, "contents" => "Error.", "@timestamp" => 2021-06-04T03:00:00.000Z, "Date" => "2021-06-04 12:00:00", "message" => "2021-06-04 12:00:00,4,Error.", "host" => "local" } { "path" => "/log/20210603_log.csv", "@version" => "1", "ID" => 3, "contents" => "Success.", "@timestamp" => 2021-06-03T02:00:00.000Z, "Date" => "2021-06-03 11:00:00", "message" => "2021-06-03 11:00:00,3,Success.", "host" => "local" } { …以下省略 Elasticsearchへ投入したデータをKibanaで整える
Kibanaは、Elasticsearchのユーザインターフェースとしては定番といえる、Elastic社のフロントエンドアプリです。Elasticsearchで得られたデータを様々な切り口から解析・可視化し、インタラクティブにダッシュボードに可視化するものです。
Kibanaのダッシュボード
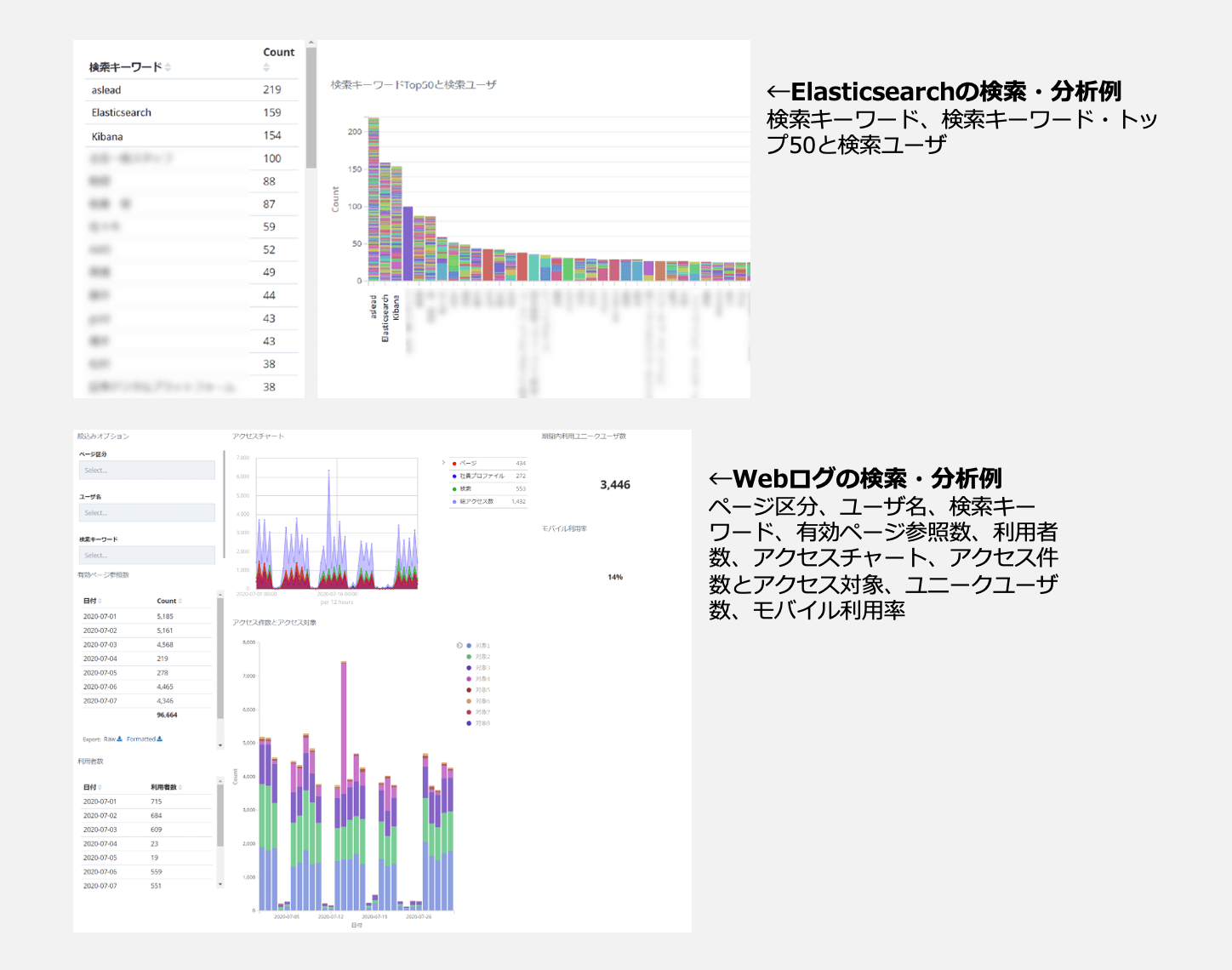
コマンドラインを使わずGUIで操作できるシンプルさ、柔軟なクエリ機能など、Kibanaを使うメリットは多々あります。Kibanaのわかりやすいインターフェースにより、従来、専門知識を持ったエンジニアのみが触れることのできた各種データが、ビジネスユーザの手にも開放されます。
Elasticsearchの導入で不安を覚えたら……
OSSはどなたでもご利用いただけますがサポートがないため、初めての方など不安に感じる方もいらっしゃるかもしれません。NRIではシステム開発管理統合サービス「aslead」から、Elasticsearchはもちろん、Beats、Logstash、Kibana、さらにはサードパーティ・ツールまで網羅する、幅広い支援を提供しています。
NRIでは自社でもElasticsearchを導入・活用しており、年間数百というプロジェクトのドキュメントをサーバに格納しています。約5万人のユーザが利用するドキュメント管理サーバ(総量100TB以上、ファイル数1億以上)における大規模運用を行っており、その知見をasleadのソリューションに反映させています。
2020年度、NRIはElastic社より、「Elastic Japan パートナーアワード 2020」ベストパートナー賞を受賞しています。これは、Elastic社のソリューション展開に貢献したパートナーを表彰するものです。aslead ソリューションへのElasticsearchの組み込み、共同セミナーの開催、Elastic認定エンジニア数などが評価されました。
Elasticsearchの導入なら、経験豊富なNRIにぜひご相談ください。
Webセミナーを開催
asleadでは、Elastic製品の導入ポイントや活用事例など、役立つ情報を定期的に発信しています。 今後の発信情報にもぜひご期待ください。
【最近のイベント例(2021年6月時点)】
見つからない情報資産に価値はない!?
~レガシーな検索システムからの脱却を目指す! 情報の徹底活用を実現する新しいソリューションとは?~
「社内の情報活用を徹底的に行うことで、生産性を向上させたい」「オープンな組織づくりを目指したい」といったニーズをお持ちの方を対象に、ウェビナーを共催しました。
NRIからは、Elasticsearchを組み込んだナレッジ検索ソリューション「aslead Search」やその事例の紹介も行いました。
【開催概要】
開催日時:2021年6月3日 14時~16時
開催者:株式会社野村総合研究所/アトラシアン株式会社/Elasticsearch株式会社
イベント詳細はこちらから